Last summer, we migrated Monzo's entire analytics infrastructure to dbt from a homegrown solution. This took significant effort, but I'm glad we did it.
This post explains why we took a bet on dbt, and why I think it's one of the most important data tools around.
SQL is a very ‘loose’ language. It doesn’t naturally push you towards good software engineering practises around re-use of code, abstraction and layering, and separation of responsibility. There are often many ways to accomplish the same objective.
Users are left to choose their own adventure with respect to defining how different SQL files relate to each other, and how they run them in the correct order. Many organisations develop their own tools for running SQL, and managing relationships between various files. These tools incur high maintenance costs.
Additionally, these tools are a great example of ‘non-differentiated heavy lifting’: being great at running SQL generally doesn’t provide any competitive advantage in the market.
Testing is challenging in SQL. There's no tooling or primitives that make this particularly easy or encouraged. Users often have to build a custom way to test that their models are correct. This doesn’t create value.
It's very hard to introspect SQL files for the actual schema they will generate. You can use a SQL parser to drive and derive structure, but this is complex. There are moves in this direction with projects like ZetaSQL, but it's still early days.
Comments are often kept in the code. They are useful, but duplication of what a particular field means is necessary for tools like Looker.
Data warehouses are a really effective way to efficiently transform data. I’d argue that you don’t really need to do much transformation before your data gets into a warehouse anymore. Load it in as raw a format as possible, and transform through SQL.
So, why not use Python, or other languages? SQL is arguably one of the most popular programming languages in the world. Many folks from across many disciplines know enough SQL to be productive. This isn’t the case with more traditional programming languages. SQL has a low learning curve to becoming productive in. Additionally, it's more focused to the job at hand, as opposed to being a general purpose language.
At Monzo, we encourage everyone to do data transformation in SQL, and take a good hard look when people are using other programming languages to do it in. We’d rather trade off absolute power and customisability in return making the 99% use case dramatically better.
dbt code is all the SQL your data warehouse supports, plus some extra functionality. You don't feel like you're writing in a custom framework. This aids with onboarding and maintainability.
A dbt model is a SQL statement. You can build a model from another model by referring to it, using the ref function. To familiarise yourself with the syntax, view the docs.
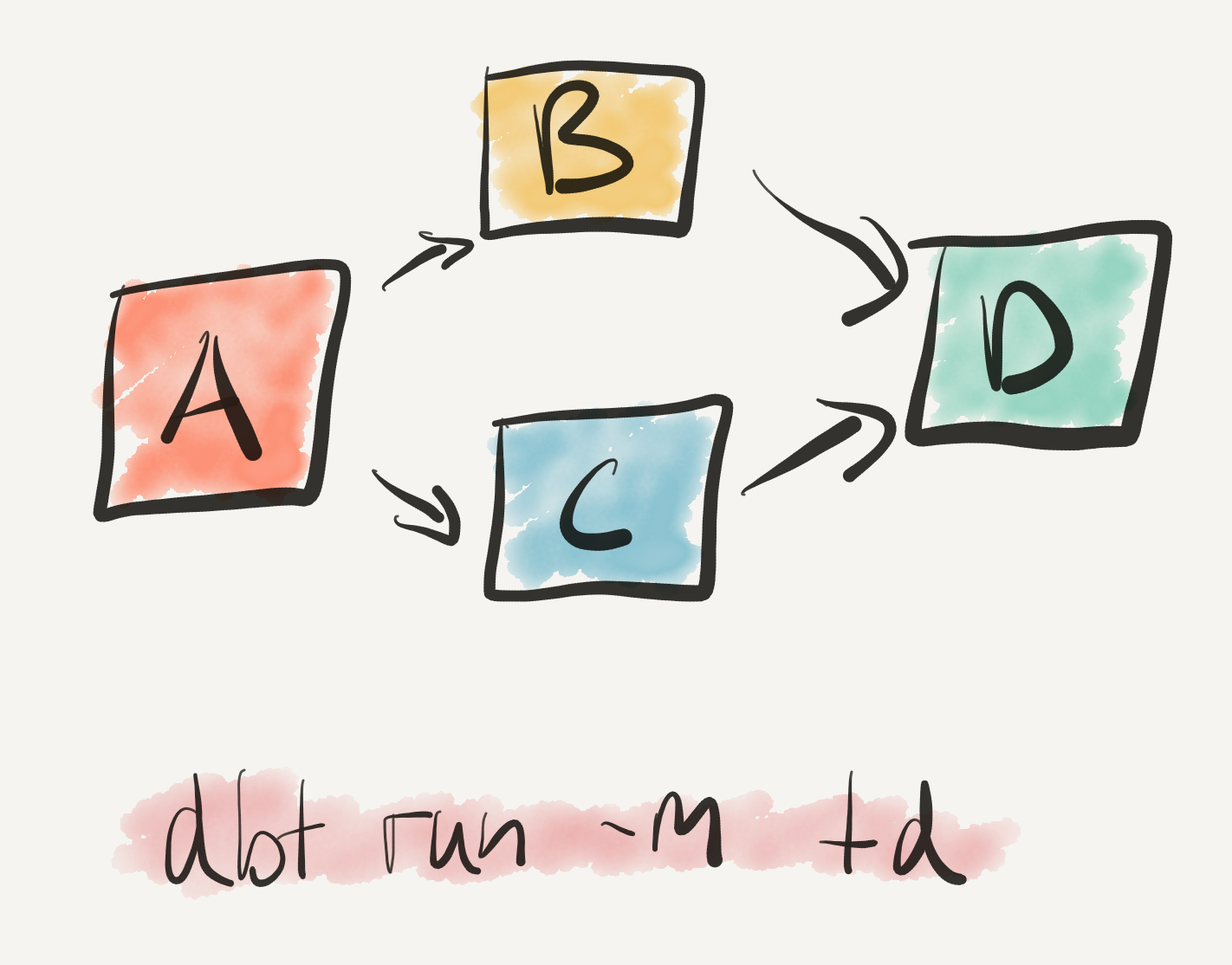
This is simple, but extremely powerful. dbt now understands how your models relate to each other as a graph. Previously, any relationship between models was implicit, and ordering of execution would need to be provided by the programmer.
This means that dbt can run them in the correct order and run tests at the correct time. In the above example, dbt will run A. If that completes successfully, it will run B and C in parallel, running D after they have both completed.
If you want to get more advanced, you can parse this graph and perform structural analysis on it, and so on. Machine readability is powerful!
A nice way to think about dbt models is to think of them as pure functions. They should accept some input data, and satisfy some clear objective without side effects, ideally in a simple manner. Structured relationships, in combination with other features, encourages modularity.
This modularity means that you can compose extremely complex models out of a set of individually simple models. This aids maintability, and helps force clarity.
‘Staging’ data is often not representative to test against, in the same way that it might be in software engineering. It’s very helpful to be able to use production data.
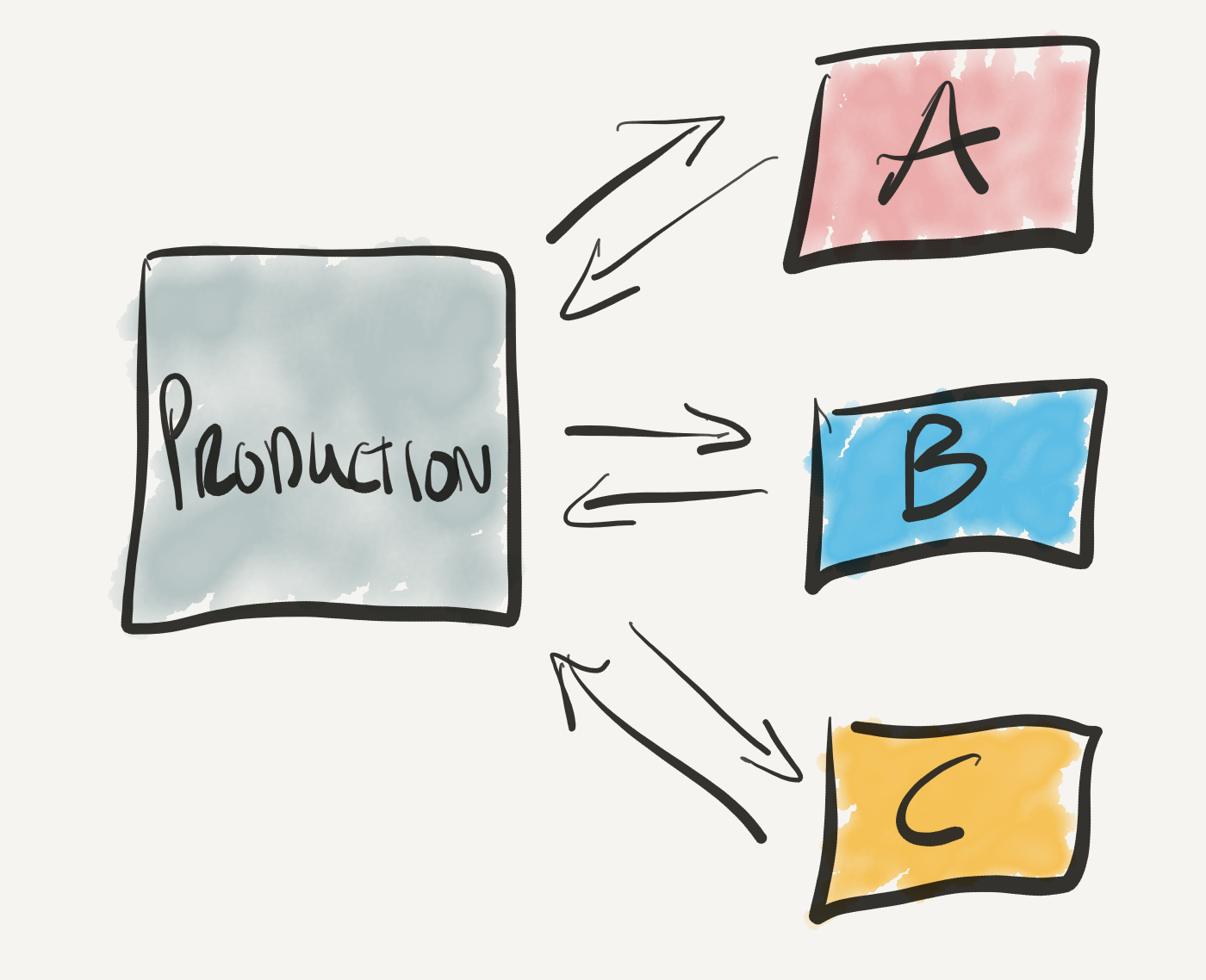
dbt allows you to de-couple the place that you read data from (or the source) from the place that you write it to, or ‘materialise’ the output of the queries you are running. This means that everyone can have their own development dataset to use, that is completely decoupled from the production dataset. They can read from it, but they can’t write to it.
Testing is a well-known technique in software engineering, but is still uncommon in data analysis and transformation. It’s a fundamental technique for ensuring correctness.
dbt allows two forms of testing: data tests, and schema tests. I find it useful to liberally scatter schema tests: it helps highlight when any invariants are broken.

Promoting testing to be a first class citizen helps up the quality bar for models written using dbt.
To supercharge your tests, run them automatically on every change you submit to your source code repository of choice, and don't allow the merging of code that fails tests.
De-coupling source data and materialisation means that running continuous integration tests becomes trivial. You can create a fresh environment per CI run, run all of your dbt models, run the tests, and delete the environment. To repeat: all of the changes that you made will be written to a completely fresh environment that is decoupled from production.
This allows you to ensure that your changes haven’t broken anything, which greatly increases reliability when you run it in production. This has historically been very challenging to do with SQL: you’d need to parameterise all of the tables that you were creating. dbt makes this a breeze.
We also use the graph that dbt outputs to enforce various checks on the models themselves. For example, all models must be tagged with a model_type, and that all models of type X must have a run tag with a certain set of values. This enforces consistency in code, and allows downstream tooling to make assumptions about what it will be dealing with.
By plumbing, I mean all of the mechanics of running the SQL to create something in the real world. dbt allows you to determine how your model is materialised, entirely separately from the SQL that is run. This means that you can switch between the following with ease:
ephemeral: models that depend on this model have the model ‘folded’ in as a Common Table Expression, or CTE.view: the model is created as a view. Models that depend on this model select from this view.table: the model is created as a table. Models that depend on this model select from this table.incremental: the model is initially created as a table. New rows are inserted. Existing rows are updated. You can exclude performing large amounts of work. Models that depend on this model select from this table.There are a few benefits to this. First, clarity. The business logic remains clear, and the boring mechanics of how the models are materialised is hidden away. Second, flexibility. If you want to turn a table into an incremental model for performance reasons, that’s a very simple change which you can experiment with quickly.
Tags are the unsung superpower in dbt. They are a list of user-provided key/value pairs. You can use tags to imbue meaning on a model, or set of models, that dbt does not natively support.
For example, we use the run tag at Monzo to delineate when we should run the model. Users tag their models with one of hourly, nightly, or weekly. When it comes to running the models later on, we simply select all models that are tagged with the appropriate run tag, and run them.
This means that users don’t have to care about how their model runs: it just does. This allows for clear contracts between data engineers and data analysts. Analysts write dbt models, data engineers figure out how to run them.
Other tags that could be useful to you:
importance: some models may be trivial, some may be critical to your business and should go through more rigorous change control. Tagging them as such provides context to people developing against it.needs_refactoring: This allows you to perform analysis over your codebase to understand whether code quality is getting better or worse. In combination with importance, it would allow you to tell if business critical models have an unsustainable level of technical debt.A beautiful nuance to dbt is that you can override a lot of the default behaviour with your own changes. Fancy changing how a particular materialisation works? You can do that!
This allows you a ‘get-out’ hatch to be able to tweak and tune it to your liking if the default behaviour doesn’t suit.
Every dbt model has a SQL file with the code of the model, and a YAML file that describes the fields, and any associated tests. This means that documentation remains close to the model in a structured format, instead of adhoc comments next to the code. dbt ships with a way of rendering these docs, which you can serve to your organisation as a static site.
A subtle but important benefit is that this documentation is machine readable. This allows you to parse this documentation, and push it out to other tools like Looker: allowing a single place to document a field.
Trade-offs exist everywhere in software engineering. Beware any posts that provide 100% praise or criticism. The world is often grey.
Now that I've finished my soliloquy, here’s a few things that are challenging in dbt.
In traditional software engineering, a way of testing whether your code is correct is by providing a set of inputs, and asserting that you get the expected outputs after you put them through a function.
This form of ‘mocking out’ input data in dbt is technically possible, but challenging to do.
dbt doesn’t perform well when you have thousands of models in a single project. Compilation times take a while, and remove from the snappy interactive experience that you’re used to.
I imagine this is an uncommon problem, exacerbated by the fact that Monzo has thousands of individual events which we build data models from.
The combination of the above makes dbt an extremely strong tool. I believe it will become 'the default' in the next few years, if it isn't already there. If you choose not to use dbt, you’ll probably waste time building a less-fully featured, buggy implementation of it yourself. Give it a serious look.